







突发!DeepSeek除夕搞炸裂,开源多模态AI模型发布,仅128颗英伟达A100训练1周,性能碾压美国企业
- 文学
- 2025-01-28 05:19:04
- 20
专题:DeepSeek为何能震动全球AI圈
刚刚,DeepSeek除夕放大招,这绝对是 AI 行业最难眠的一夜了。
1月28日凌晨,人工智能社区Hugging Face显示,DeepSeek刚刚发布了开源多模态人工智能模型Janus-Pro,拥有10亿和70亿参数规模。其中Janus-Pro-7B在GenEval和DPG-Bench基准测试中击败了OpenAI的DALL-E 3和Stable Diffusion。
简单来说,这个模型既能让AI读图(基于SigLIP-L),又能让AI生图(借鉴LlamaGen),分1.5B和7B两个大小。要知道,GPT-4o的图片生成多模态模型至今没开放。
它到底有多么厉害?给你看看DeepSeek给的案例。
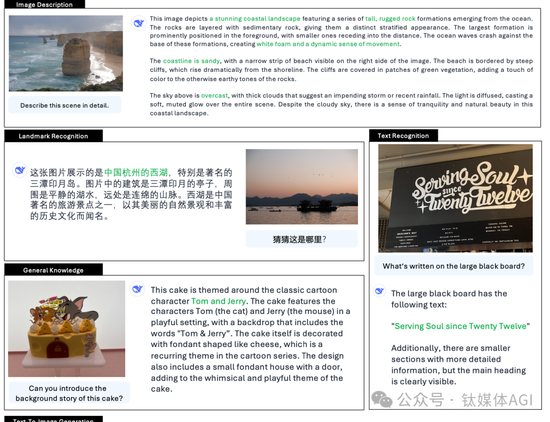
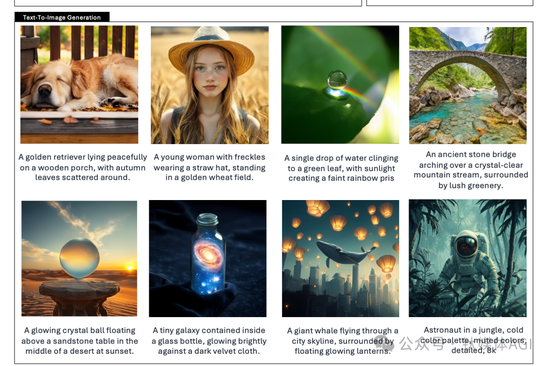
它能解答图片在杭州西湖,也能根据提示词生成惟妙惟肖的图片。
事实上,DeepSeek一直在研发多模态生成式AI模型。
2024年前后,该公司推出Janus,这是一种统一理解和生成的开源多模态模型(MLLM),它将视觉编码解耦,以实现多模态理解和生成。
Janus 基于 DeepSeek-LLM-1.3b-base 构建,该库在大约 500B 个文本标记的语料库上进行训练。对于多模态理解,它使用 SigLIP -L作为视觉编码器,支持 384 x 384 图像输入。对于图像生成,Janus 使用此处的标记器,下采样率为 16。
2024年11月13日,JanusFlow 发布,一种用于图像生成的具有校正流的新型统一模型。
简单来说,JanusFlow是一个功能强大的框架,它将图像理解和生成统一到一个模型中。JanusFlow 引入了一种极简架构,将自回归语言模型与最先进的生成模型方法整流流相结合。我们的主要发现表明,整流流可以直接在大型语言模型框架内进行训练,无需进行复杂的架构修改。
2025年开年,Janus全面升级到高级版Janus-Pro。
具体来说,Janus-Pro 是一种新颖的自回归框架,它将多模态理解和生成统一起来,将视觉编码解耦,以实现多模态理解和生成。它通过将视觉编码解耦为单独的路径来解决以前方法的局限性,同时仍然使用单一、统一的转换器架构进行处理。
这种解耦不仅缓解了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。
不过,Janus-Pro架构与Janus相同。总体体系结构的核心设计原理是将视觉编码解析,以进行多模式的理解和生成。我们应用独立的编码方法将原始输入转换为功能,然后由统一自回归Transformer处理。为了进行多模式理解,我们使用siglip 编码器从图像中提取高维语义特征。将这些特征从2-D网格平坦为1-D序列,并使用理解适配将这些图像特征映射到LLM的输入空间中。对于视觉生成任务,我们使用的VQ令牌将图像转换为离散ID。将ID序列平坦为1-D之后,我们使用一代适配器将与每个ID相对应的代码簿嵌入到LLM的输入空间中。然后,我们将这些特征序列加和形成多模式特征序列,然后将其送入LLM进行处理。除了LLM中的内置预测头外,我们还利用一个随机初始化的预测头来进行视觉生成任务中的图像预测。整个模型遵循自回归框架。
Janus-Pro 超越了之前的统一模型,并且达到或超过了特定任务模型的性能。Janus-Pro 的简单性、高灵活性和有效性使其成为下一代统一多模态模型的有力候选者。
Janus-Pro 是基于 DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base 构建。
最重要的是训练:我们在单个训练步骤中根据指定的比率混合所有数据类型。我们的 Janus 使用 HAI-LLM [15] 进行训练和评估,这是一个构建在 PyTorch 之上的轻量级且高效的分布式训练框架。整个训练过程在 1.5B/7B 模型的 16/32 个节点的集群上花费了大约 7/14 天,每个节点配备 8 个 Nvidia A100 (40GB) GPU。
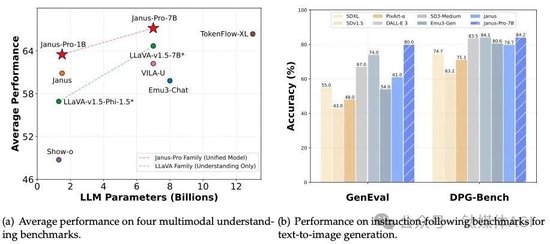
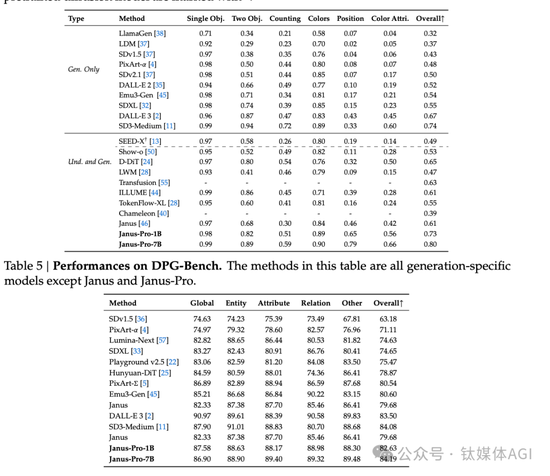
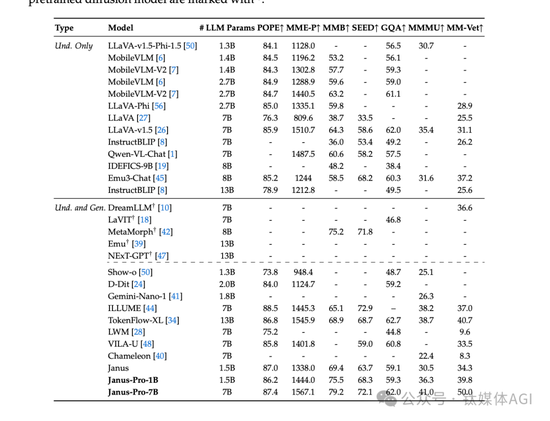
对外展示的多个基准测试显示,Janus-Pro 卓越的多模态理解能力,并显着提高了文本到图像的指令跟踪性能。具体来说,Janus-Pro-7B在多模态理解基准MMBench 上取得了79.2的分数,超越了Janus (69.4)、TokenFlow (68.9)等最先进的统一多模态模型,和MetaMorph (75.2)。此外,在文本到图像指令跟踪排行榜 GenEval中,Janus-Pro-7B 得分为 0.80,优于 Janus (0.61)、DALL-E 3 (0.67) 和 Stable Diffusion 3 Medium(0.74)。
Janus-Pro-7B 在 GenEval 上获得了 80% 的总体准确率,这优于所有其他统一或仅生成的方法,例如 Transfusion (63%) SD3-Medium (74%) 和DELLE-E 3 (67%)。这表明我们的方法具有更好的指令跟踪能力。另外,Janus-Pro 在 DPG-Bench 上获得了 84.19 的分数,超过了所有其他方法。这表明 Janus-Pro 擅长遵循密集的指令来生成文本到图像。
目前,相关代码已经放在了GitHub当中。
https://github.com/deepseek-ai/Janus?tab=readme-ov-file
我们非常期待接下来DeepSeek能够带来优异的多模态(如文生图、文生视频)等功能和表现,这可能会让OpenAI、Meta,甚至是英伟达会更加恐慌。
最后的最后,还是要提醒,DeepSeek已经限制新用户注册了,也就是锁区了,海外的朋友需要买虚拟号注册:近期DeepSeek线上服务受到大规模恶意攻击,为持续提供服务,暂时限制了+86手机号以外的注册方式,已注册用户可以正常登录,感谢理解和支持。
相关文章
热门文章

乐购陷入“变态经理”骗局,承诺“750英镑折扣券”
2024-12-28
以色列在加沙北部的新策略引发了人们对种族清洗运动的担忧
2024-12-28
伊朗选手拜特·萨耶的残奥会金牌因悬挂“令人反感”的国旗而被剥夺
2024-12-28
医生的简单饮食,让你在短短四周内减掉一英寸的腰围
2024-12-28
“可爱的”爷爷在向家人隐瞒秘密后被发现死在停车场
2024-12-28
杜丽莎取消关注《我是名人》,因为秘密不和的谣言四起,她最终被冷落
2024-12-28
听听宾夕法尼亚州伊利市企业主和选民的看法。他们可以帮助决定白宫。
2024-12-28
在《龙珠火花零》多人游戏发行几天后,作弊问题浮出水面
2024-12-28
有话要说...